Using ACRCloud to Identify Copyrighted Audio Content

Consumer applications like Shazam have been around for years, but only recently has using Automated Content Recognition (ACR) tools in enterprise software been easy and affordable. As a major podcast producer, the team at Barstool has to verify that any new podcast episodes we upload don’t contain copyrighted content that we aren’t licensed to use prior to publishing. Up until recently, this process was manual and laborious. The engineering team set out to fix that.
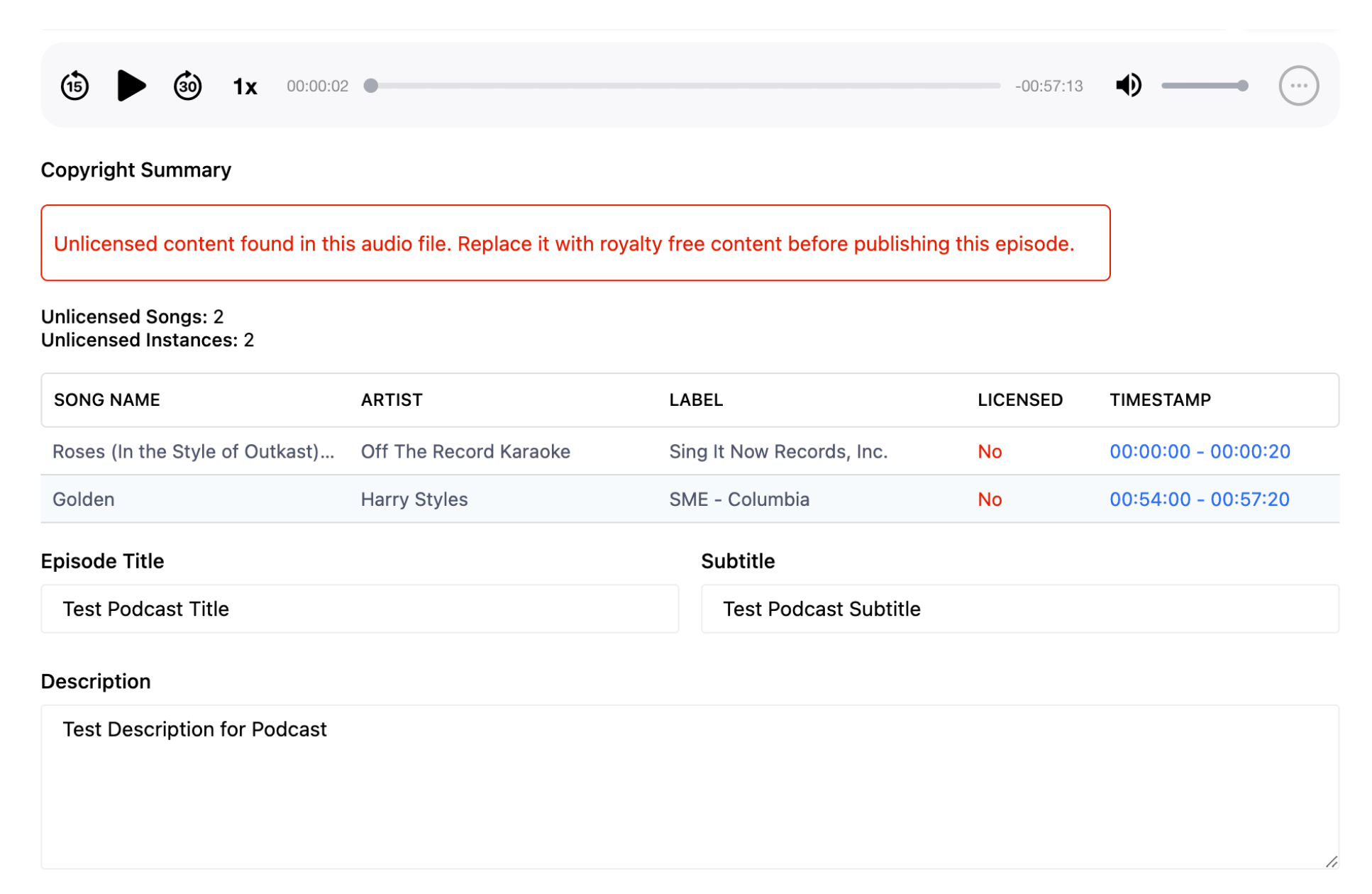
The goal was to create an automated system identify any copyrighted audio at upload-time. We could then compare the identified content with a whitelist of labels that we license for use in podcasts, and display a simple UI so producers can verify at-a-glance that we have rights to use all of the content prior to publishing. If a section of audio comes back as containing unlicensed content, the producer would then recut the episode with alternate content in its place.
After evaluating several vendors, we chose to go with ACRCloud. They’re a relatively new startup, but have made a name for themselves in their short time in the industry. Their music identification service allows you to upload an audio or fingerprint file for identification. While uploading a full podcast audio file was tempting, in practice the transit and processing time was too long for our purposes.
ACRCloud provides a number of tools and SDKs on their GitHub to interface with their APIs. To prove out the concept we used the Python Scan Tool. This generates fingerprint files for every 10 second segment of the input file, then uploads them to the ACRCloud API. The output is parsed as either JSON or CSV locally. While we wouldn't use this tool directly in our infrastructure, it helped us to understand & prove out the process. After vetting the data, we were ready to replace the python script with a direct integration in our CMS.
Under the hood, the Python script uses the ACRCloud Extractor Tool to generate fingerprint files. The fingerprint files are generated for a specific span of time based on the CLI input. When each fingerprint file was ready, a request was made to the ACRCloud's identification API. These endpoints require each upload be signed to verify the payload integrity, so each request required an SHA1 hash to accompany the request. Below is the NodeJS to send the request
async function _identifyFingerprintFile({ file, offset, options }) {
//ACRCloud requires a header signing the payload
const data = Buffer.from(await fs.readFile(file))
let current_data = new Date()
let timestamp = current_data.getTime() / 1000
let stringToSign = _buildStringToSign(
'POST',
options.endpoint,
options.access_key,
options.data_type,
options.signature_version,
timestamp
)
//Creating signature for the request
let signature = crypto.createHmac('sha1', options.access_secret)
.update(Buffer.from(stringToSign, 'utf-8'))
.digest().toString('base64')
let form = new FormData()
form.append('sample', data)
form.append('sample_bytes', data.length)
form.append('access_key', options.access_key)
form.append('data_type', options.data_type)
form.append('signature_version', options.signature_version)
form.append('signature', signature)
form.append('timestamp', timestamp)
const body = await http
.post('https://' + options.host + options.endpoint, {
method: 'POST',
body: form
})
.json()
return { file, offset, result: body }
}
function _sign(signString, accessSecret) {
return
}
Our first performance improvement was to asynchronously upload the fingerprints for identification in parallel rather than one at a time. This reduced the total processing time greatly, while adding comparatively little complexity. This would all live in BQE so we aren't resource constrained per-process and don't have an upper run-time limit to worry about.
While the actual identification was performant, we noticed the tool took exponentially longer to generate fingerprints the further into the audio file they were, meaning generating a fingerprint from 0-10 was almost instant, while each subsequent fingerprint would longer and longer to generate. This is common behavior with applications that require seeking to a specific location in a media file, as the underlying mp3 library has to decode every frame to make sure your seek command is frame-accurate.
While FFMPEG can have this same issue, there are several ways to make frame-accurate seeking faster. We’ve used some of these methods when clipping live video so we were familiar with the problem. To speed up ACRCloud, our solution was to generate mp3 clips using FFMPEG map function with the flag -segment_time flag set to 10 seconds.
async createMp3Chunks({ input, eventId }) {
return new Promise((resolve, reject) => {
//_createAudioFfmepgProcess is a helper that creates an ffmpeg
//process with a standard bitrate, refresh rate & audio codec
const ffmpegProcess = _createAudioFfmpegProcess(input, eventId)
ffmpegProcess
.addOutputOptions(['-c copy', '-map 0', '-segment_time 00:00:10', '-f segment', '-reset_timestamps 1'])
.save(`temp/${eventId}-segment-%04d.mp3`)
.on('start', function (commandLine) {
console.log(`Segment process spawned Ffmpeg with command: ${commandLine}`)
})
.on('end', async (event) => {
console.log('event', event)
console.log(`${eventId} - File segmented successfully`)
//have to read the temp directory for matching files, since
//ffmpeg wont return output files as part of stdout
const tempFiles = await fs.readdir('temp/')
resolve(tempFiles.filter((file) => file.indexOf(`${eventId}-segment-`) > -1))
})
.on('error', reject)
})
}We then could take all of the generated mp3s segments and process them using the ACR extractor tool in parallel. Once we have an array of fingerprint files we had to tie everything together and generate a response with the specific time ranges where copyrighted content was found. This reduced our processing time to ~1 minute for a 1 hour long audio file.
Once we had a JSON response with all of the licensed content used in the audio file, all that was left to do was return the value back to our Podcast API. Below is a view of that our producers see if an audio file is uploaded with unlicensed content: