Long-Running Jobs on the Barstool Queue Engine

Here at Barstool we love the Serverless framework, which has enabled us to build high-concurrency low-cost services. Our infrastructure relies heavily on Lambda, API Gateway, SQS & SNS all of which are easily created and managed in our serverless.yml files. On top of a low DevOps overhead, Serverless has a mature developer toolset has been critical to rapidly releasing major features at the fast pace of Barstool.
Since Barstool creates tons of video & audio content on a daily bases that we distribute across many different platforms, the engineering team has to manage workloads that require minutes or hours of compute time to complete. Because of lambda's execution runtime limits, we needed a way to process those long living jobs that lambda wasn't well suited for. Our solution would have to run in a container for portability, and supported a range of different static binaries & node packages. Most importantly, tasks should have no upper limit for total runtime. We also wanted our deployments to be stateless and to easily slot into our existing Serverless infrastructure. It also had to have low developer overhead for local development and be easy to manage from a DevOps point of view.
Our solution, the Barstool Queue Engine, was purpose-built with these requirements in mind. We use the sqs-consumer, one of the many great open-source packages by the BBC, to receive messages sent by our other services. Each BQE service runs a single node.js codebase packaged into a single container with a dedicated SQS queue, ECS Service, and task definition. This allows us to control the specific resources designated for each task; messages in the video processing queue run against video tasks that have more RAM than dedicated audio tasks, while multi-threaded tasks can have multiple CPU cores available per container.
To accomplish this, container images are built once by GitHub actions, and tasks definitions & services are created and deployed using a matrix strategy. Each service has a Cloudwatch alarm triggered based on how many unread messages are in the queue that manages scaling the individual services. A private SDK for sending SQS messages and replying via SNS enforces standardized communications between our various services and BQE. Below is a simplified diagram of the message flow.
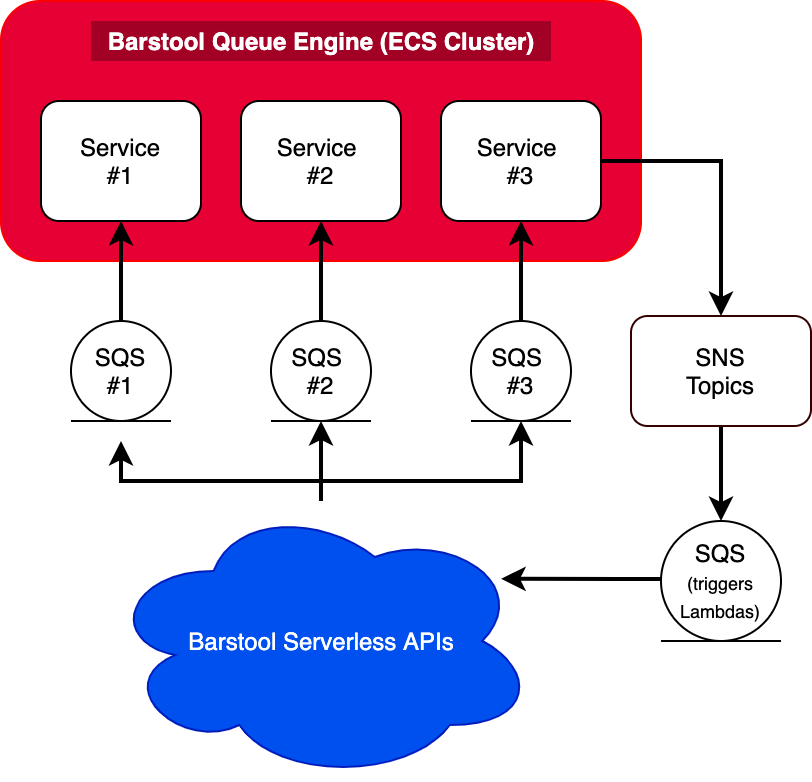
This pattern allows us to keep BQE dumb- it only knows the information necessary to complete the task and how to notify the proper SNS topic when the task is complete. We are able to support developer-friendly features such as branch deploys with minimal effort.
Finally, with some light code changes, it would also allows us to replace the ECS cluster with SQS backed lambda if AWS ever increases the execution time.