Resilient Multi-part file uploads to S3

Just about anyone who has spent time developing web apps has had the need to handle file uploads. We live in a (literal) web of profile pics, gifs, memes, live streams, vlogs, etc, etc. With the rise of services like AWS S3, the task of handling uploads and storing file objects has, for the most part, become trivial. This is obviously a great thing and for most web apps, anything more than a basic integration with AWS S3 would be overkill. Like many other engineering teams, at Barstool we are big on keeping it simple and not over-engineering. In the (paraphrased) words of Knuth
"Premature optimization is the root of all evil"
In mid-2019, the engineering team at Barstool was in the early stages of the odyssey that has been replacing wordpress with our own in-house CMS - Barstool HQ. We were in the midst of pumping out new features almost weekly, in a race to gain internal buy-in to the new and unfamiliar platform. If we were going to enable our content team to be productive in HQ, a proper media management module was an absolutely crucial. Blog posts need thumbnails, bloggers need avatars, video posts require... videos. So we quickly built the internal tools for users to upload new files, browse existing files, and to attach those files wherever they might be needed.
Phase 1
By late 2019, HQ had started to gain traction internally. Some bloggers were operating entirely within HQ and consequently usage of our file uploader skyrocketed. With increased usage, unaccounted-for edge cases and plain old bugs naturally followed. Bugs were squashed and some edge-cases covered, and work generally carried on as usual.
Things started to get interesting when a member of the content team made a request for bulk image uploads. It was a simple enough request and it would provide a big boost in productivity for end-users. The changes required to support multiple uploads didn't seem too difficult either. Our initial implementation had consisted of a drag-n-drop uploader component:
<Uploader
multiple={false}
accept={this.props.fileType ? this.fileTypes[this.props.fileType] : '*'}
errorMessage={this.state.errorMessage}
onCancel={this.reset}
onDrop={this.handleDrop}
onRetry={this.reset}
progressAmount={this.state.progressAmount}
/>While bulk of the work occurred in the handleDrop method:
handleDrop = async (acceptedFiles, rejectedFiles) => {
if (acceptedFiles.length > 0) {
const extension = acceptedFiles[0].name.split('.').pop()
const data = await mediaApi.getSignedUrl({ extension, content_type: acceptedFiles[0].type })
await mediaApi.uploadToS3(data.upload, acceptedFiles[0], this.onUploadProgress)
const { provider } = this.props
const mediaObject = await mediaApi.create({ provider, key: data.key, title: filename })
this.props.onCompleted(mediaObject)
this.reset()
} else if (rejectedFiles.length > 0) {
this.setState({
errorMessage: 'Upload failed'
})
}
}To add support for bulk uploads, we moved the logic responsible for communicating with the mediaApi service to a function handleUploadFile while handleDrop would now only be responsible for iterating through the files and passing them to as arguments to handleUploadFile:
async function handleUploadFile(file, index) {
const { type, name, size } = file
const key = `${name}-${index}`
setUploadProgress(key, { loaded: 0, total: size })
const extension = last(name.split('.'))
const data = await mediaApi.getSignedUrl({ extension, content_type: type })
await mediaApi.uploadToS3(data.upload, file, progressData => onUploadProgress(key, progressData))
const mediaObject = await mediaApi.create({ provider, key: data.key, title: name })
incFilesUploadedCount()
onFile(mediaObject)
return mediaObject
}
async function handleDrop(acceptedFiles, rejectedFiles) {
if (acceptedFiles.length > 0) {
setFilesToUploadCount(acceptedFiles.length)
const mediaObjects = await Promise.all(acceptedFiles.map(handleUploadFile))
if (onCompleted && isFunction(onCompleted)) {
onCompleted(mediaObjects)
}
reset()
} else if (rejectedFiles.length > 0) {
setErrorMessage('Upload failed')
}
}During QA, this worked great. We were able to drop multiple files into the uploader and they'd all get uploaded concurrently thanks to Promise.all. However, once we released it quickly became apparent that the simple solution above would not be adequate for a number of reasons:
- Due to the nature of
Promise.all, one failed upload would cause the entire process to fail. - Our admin api's have maximum concurrency limits, which it turns out were occasionally being exceeded when a single user opens 40 additional connections while uploading 40 files
- There is no way for users to 'retry' failed uploads, they have to start from the beginning and select all their files again, this is obviously very frustrating for users.
Phase 2
So we went back to the drawing board and determined that with the following improvements, we would cooking with gas:
- Upload files in batches with a maximum concurrency set, preventing the maximum concurrency limit imposed by our api from being exceeded.
- For each batch of uploads, add automated retry logic in order to mitigate non-fatal errors caused by network conditions, etc
- In addition to automated retry logic, track failed uploads and allow user to manually retry the failed uploads
Here is the helper function we came up with, mapAsync which powers the batched upload logic. It takes as arguments: an array of items, a concurrency limit, and a callback which will be invoked with each item, respectively.
async function mapAsync(items, concurrency = 1, handler) {
let results = []
let failures = []
let index = 0
while (index < items.length) {
const batch = items.slice(index, index + concurrency)
try {
const _results = await Promise.all(batch.map(handler))
results = [...results, ..._results]
} catch (err) {
failures = [...failures, ...batch]
}
index += concurrency
}
return { results, failures }
}For the automated retry logic, we wrote a simple but powerful helper function, withRetries which takes as arguments: an async function, the number of retries to allow, and an error. Note that the err argument is meant to be passed when the function is invoked, but rather from within recursive calls after an error.
async function withRetries(fn, retries = 3, err = null) {
if (!retries) {
return Promise.reject(err)
}
return fn().catch(err => {
return withRetries(fn, retries - 1, err)
})
}It should be clear what is going on here, but basically the callback fn is invoked and if it rejects, then withRetries is recursively called with retries - 1, it will continue to do this either until fn succeeds or retries is exhausted, at which point an error is thrown back to the caller.
With these two helper functions we made the following modifications to the code in our FileUploader component:
async function handleRetry(files) {
try {
await handleDrop(files)
} catch (err) {
setErrorMessage(`Uploading failed again, please try again later`)
}
}
async function handleDrop(acceptedFiles, rejectedFiles) {
if (acceptedFiles.length > 0) {
// update progress state with all files to be uploaded prior to processing - because processing is done in batches this step is necessary beforehand in order to achieve realistic progress
acceptedFiles.forEach(({ name, size }) => setUploadProgress(name, { loaded: 0, total: size }))
setFilesToUploadCount(acceptedFiles.length)
// upload files in asynchronous batches because concurrency limits can cause uploads to fail if surpassed resulting in entire upload hanging
// because processing happens in batches, its possible that only certain batches fail to upload, so there can be successes and failures (rather than just one or the other like if this was all wrapped in a promise.all)
const { results: allMediaObjects, failures } = await mapAsync(
acceptedFiles,
4,
async (file, index) => await withRetries(async () => await handleUploadFile(file, index))
)
// if there are failures, we could allow retrying the upload with just those items, that way we wont re-upload any successful uploads
if (failures.length) {
setErrorMessage(`${failures.length} files failed to upload, would you like to retry uploading these files?`)
setFilesToRetry(failures)
} else {
reset()
if (onCompleted && isFunction(onCompleted)) {
onCompleted(allMediaObjects)
}
}
} else if (rejectedFiles.length > 0) {
setErrorMessage('Upload failed')
}
}And the end-result, when uploading four files and the fourth file fails to upload, the user can retry manually, and the uploader will pick back up where it left off, only attempting the fourth file again:
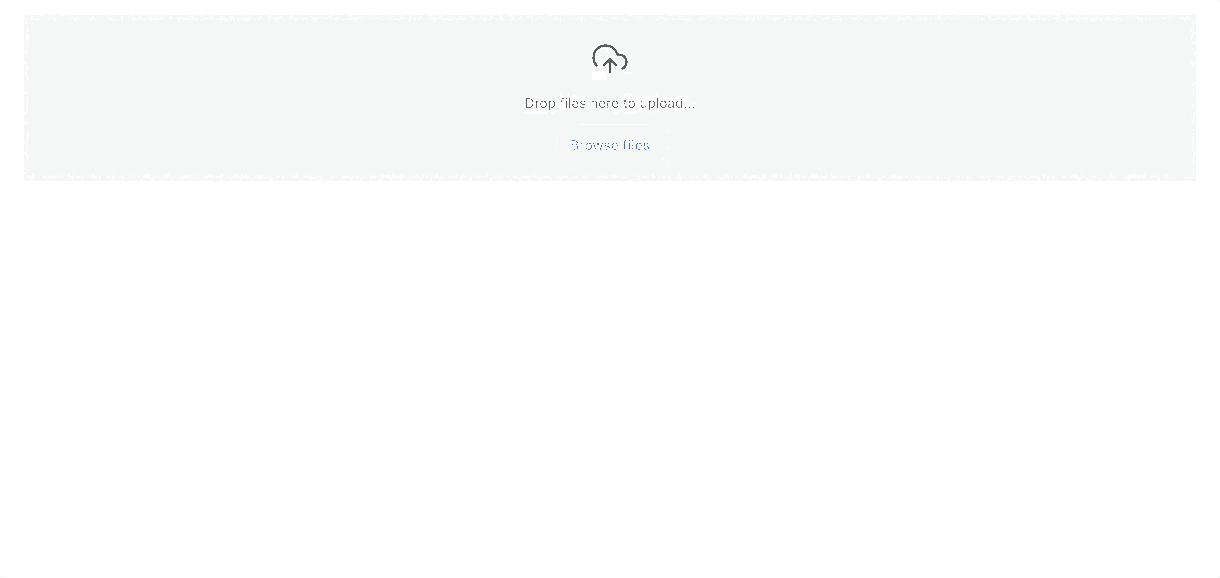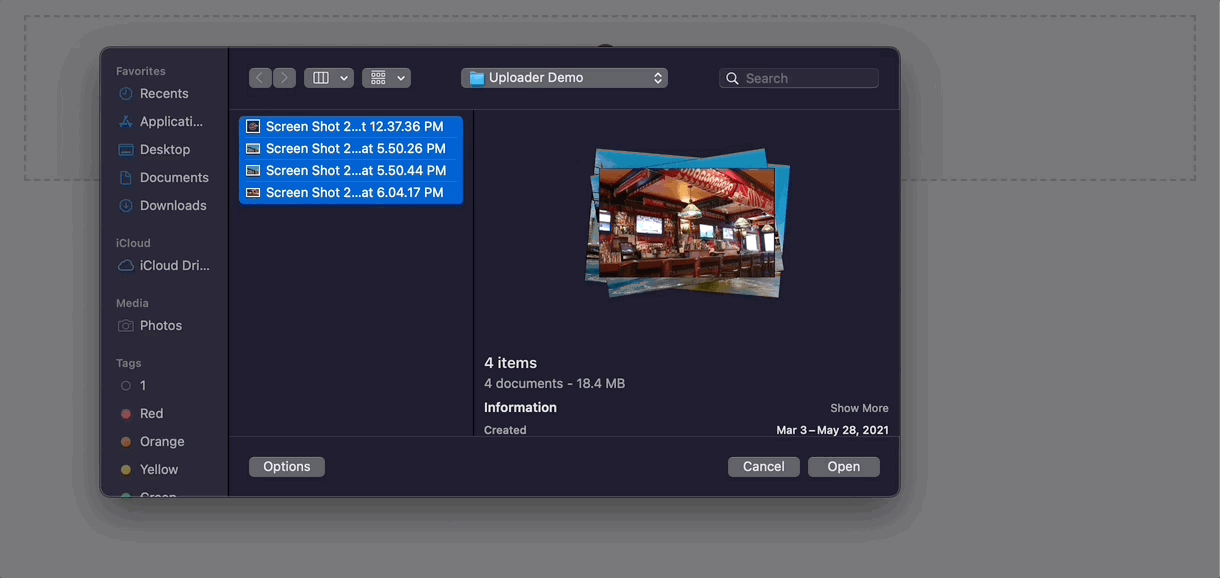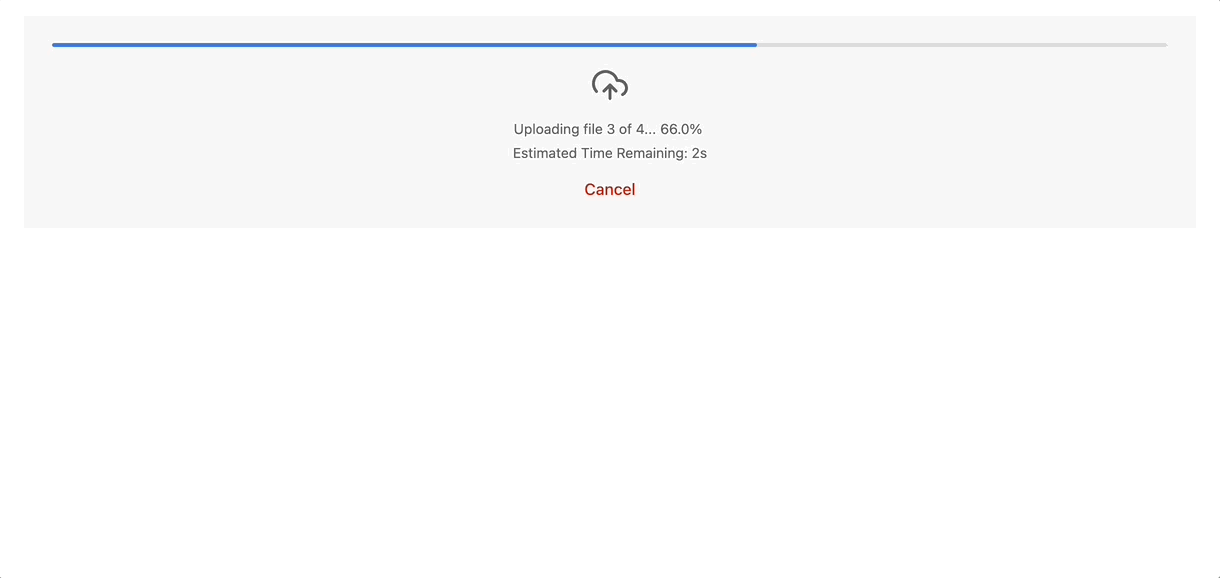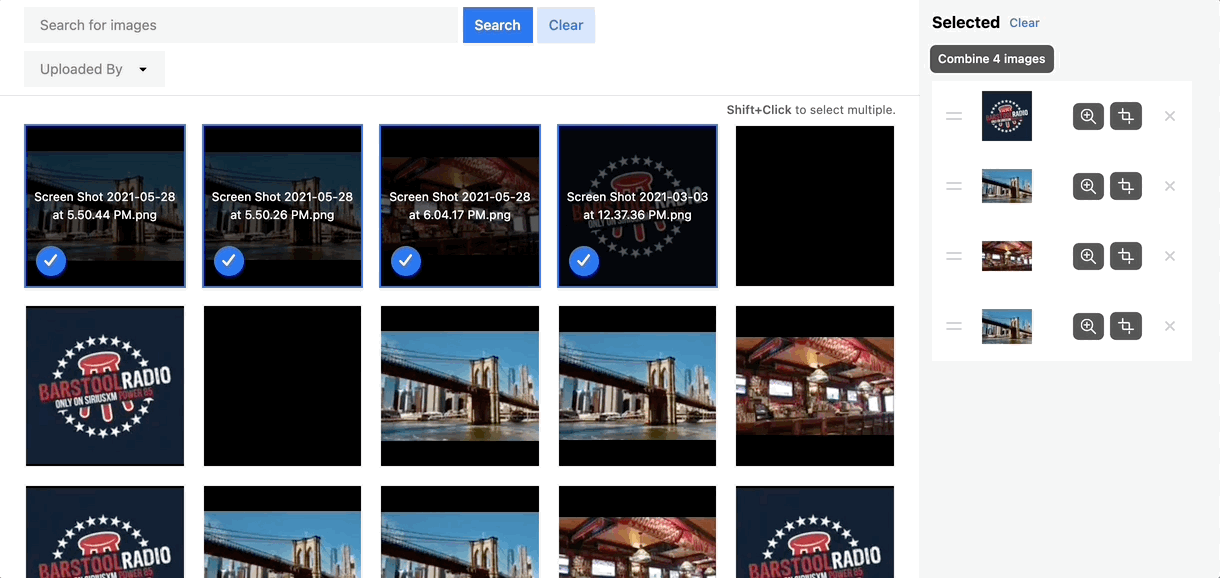
The compounding effects of the batched uploads and automated retry logic actually made it rather tedious to test the manual retry logic - generally it's a pretty good sign when it's hard to break something.
After the changes were released, complaints dropped off almost entirely. We were very satisfied: without too much effort, we had iterated on our initial uploader, reusing most of our existing code to build a resilient uploader that could handle any number of files. I tested a bulk upload of 100 high-res images from Unsplash, and the uploader churned right through them, no failures.
Phase 3
For several months, no one touched the code of the uploader component. Our primary users early on were bloggers who primarily uploaded images or short video clips that they wanted to use in blog posts, and the uploader continued to work great for them.
During that time, however, the engineering team was working on a big project to bring all our video management functionality in-house. As part of bringing video management in-house, we'd need to have the capability to handle large files, often up to and sometimes even over 10 GB.
We were ahead of the curve this time, before anything was released we were aware of the fact that we had a big problem: The maximum part size of an object being uploaded to S3 is 5 GB. Without a workaround, this was a show-stopper for moving video management in-house.
S3 supports multi-part uploads as documented here Uploading and copying objects using multi-part upload and so did some research to figure out what our exact approach would be. We browsed the GitHub, NPM, etc. for any existing solutions, surely we weren't the first engineering team to run into this issue.
Our head of engineering, Andrew, found this really great article Multipart uploads with S3 pre-signed URLs which outlines the server-side changes needed to support multi-part uploads. Using the article as a reference, we were able to very quickly implement the necessary endpoints for supporting multi-part uploads. The endpoints we implemented were as follows:
POST /upload-multipart { content_type: String, extension: String, filename: String, parts: Number }:partsis the number of chunks we will break the file into when uploading, the response includes{ bucket: String, key: String, location: String, upload_id: String, urls: [String] }whereurlsis the array of endpoints that we will use to upload each corresponding chunk.POST /upload-multipart/complete { key, bucket, upload_id, etags }which is hit after all the chunks have been upload, this stage’s job is to inform to S3 that all the parts were uploaded. By pass the etag of each part to this endpoint, S3 knows how to construct the object from the uploaded parts.
Next, we came across UpChunk, which just so happens to be built by our video provider, Mux. According to the ReadMe, UpChunk is "a JavaScript module for handling large file uploads via chunking and making a put request for each chunk with the correct range request headers." This is exactly the type of library we were looking for. Unfortunately, after digging deeper and even asking the mux team about it directly, it was apparent that it would not be compatible with multi-part uploads that S3. But not all was lost - the UpChunk source is very tiny and easy to comprehend, so using that as a starting point and reference, while modifying what we needed to make it compatible with our system, we were able to make our own chunk uploader that was compatible with S3 multi-part uploads.
I remember very clearly that all of this discovery was done during a Friday afternoon in September of 2020. I was heads down on the code all evening and had something nearly working by around 9pm. Our new ChunkUploader module worked as follows:
- Initialize uploader with
fileto upload andgetEndpointswhich is either an array of endpoints or an async function which returns the endpoints after being invoked. Additionally, anonUploadProgresscallback can be passed, which will receive progress events as chunks are uploaded, this is useful for displaying a progress bar. - Call
uploader.upload()which, as its name implies, kicks of the upload process.upload()first calculates the number of chunks to break the file into and subsequently calls thegetEndpointsmethod with that number of chunks to get the array of endpoints that each chunk will be uploaded to. - Next, a private method
_sendChunkswhich similar to theFileUploadercomponent, uploads the chunks in batches set to a maximum concurrency, each of the chunks can be retried up to 5 times exponential backoff upon failures. To get each chunk, each endpoint return fromgetEndpointsis iterated, and each file is sliced fromindex * chunk size in bytestoindex + 1 * chunk size in bytes, whereindexis the current index of each endpoint as they are iterated through. - Upon successful upload of each chunk, the
etagreturned is stored in an array corresponding to each chunk. uploader.upload()returns an object with the shape:{ key: String, bucket: String, upload_id: String, etags: [String] }, this will be used in to make the request toPOST /upload-multipart/completeto finish the multipart upload process.
And here's what that code looks like:
async function handleUploadFile(file) {
if (cancelUploadRef.current) {
throw new CanceledUploadError()
}
const { type, name } = file
const key = `${name}`
const extension = last(name.split('.'))
// initialize uploader with file object and getEndpoints callback for fetching pre-signed urls for each file part
const uploader = new ChunkUploader({
file,
cancelRef: cancelUploadRef,
getEndpoints: ({ parts }) => {
return mediaApi.requestMultipartUpload({
extension,
content_type: type,
filename: name,
parts
})
},
onUploadProgress: (progressData) => {
onUploadProgressThrottled(key, progressData)
}
})
// complete chunk upl
const multipartData = await uploader.upload()
const signedUrl = await () => mediaApi.completeMultipartUpload(multipartData)
const mediaObject = await mediaApi.create({ provider, key: signedUrl.key, title: name, duration: audioFile?.duration })
incFilesUploadedCount()
return mediaObject
}To keep our codebase as simple as possible, we use this as the upload logic for all of our files, not just big ones. Since files are uploaded in 8 MB chunks, so anything smaller than 8 MB is just a single chunk, nice and consistent!
Another nice benefit of uploading in chunks is that we can retry individual chunks in addition to retrying individual files, so we now have an extra layer to our retry logic to combat network issues. Additionally, we track upload progress per-chunk-url, which gives us progress data on a very granular level, allowing for some nice-to-haves like displaying 'Estimated time remaining' for uploads. 'Estimated time remaining' actually proved to be a very valuable tool for producers, who spend a lot of time waiting for files to upload: knowing the time remaining, they can continue working on other stuff and come back to the upload once the file is close to being fully uploaded.
Closing Thoughts
Since releasing the changes ~9 months ago, I can't think of a single complaint that we've received related to failed uploads that could be attributed to our upload logic. A lack of complaints does not necessarily mean that there are no issues, but it's a promising sign considering we consistently upload several hundred videos and several thousand images per month.
Future Improvements
There are always improvements to be made. Given that we are a small engineering team with a ton of shit to do, we try to make those changes when we know that they are needed and that they will have a noticeable impact on the productivity of our users. Regardless, here's a list of some things that are on our radar that we'd like to improve at some point:
- Support uploads in the background - a simple starting point would be to store a global reference to the upload process so that the user can leave the upload page and continue work while the uploader continues to work in the background. Upon successful upload, the user would receive a toast notification with a link to the new file
- Better support for changes to network conditions like online/offline events, if the browser loses connection, we should immediately pause the upload process and allow the user to continue once their connection is restored.
- Improvements to 'Estimated time remaining' calculation. Our current implementation works very well for larger files, the algorithm being
((milliseconds elapsed / progress amount) - milliseconds elapsed)whereprogressAmountis a decimal between 0 and 1. The current algorithm is nice and simple, it first calculatesmillisecondsTotal(estimated total time that the upload will take) by dividingmillisecondsElapsed(time since start of the upload) byprogressAmount(decimal between 0 and 1 indicating the current progress, 50% progress being 0.5), and then substractingmillisecondsElapsedfrommillisecondsTotal. This works really nicely and gets more accurate with each second that upload is running, however it always takes a few seconds to 'calibrate', which for smaller files means that it is almost never accurate. - Last but not least, code improvements: a lot of love has gone into the
FileUploadercomponent and relatedChunkUploader, but there's more we could do to make it reusable, or even potentially open-source it some day.
Hopefully you've learned a thing or two about handling file uploads in a resilient manner and I also hope that you've learned about how the culture Barstool engineering team culture and how we tackle problems. If you're interested in working on problems like this (or not, if file uploads aren't for you, we do a lot of other stuff too) check out our openings here, we're actively hiring. Thanks for reading.